Blog
Blogs
AI in Healthcare: Lessons Learned from Our Early Experiments With LLMs and SLMs
BLOG by
CitrusBits
September 16, 2025
#Citrusbits #Technology #AI #LLMs
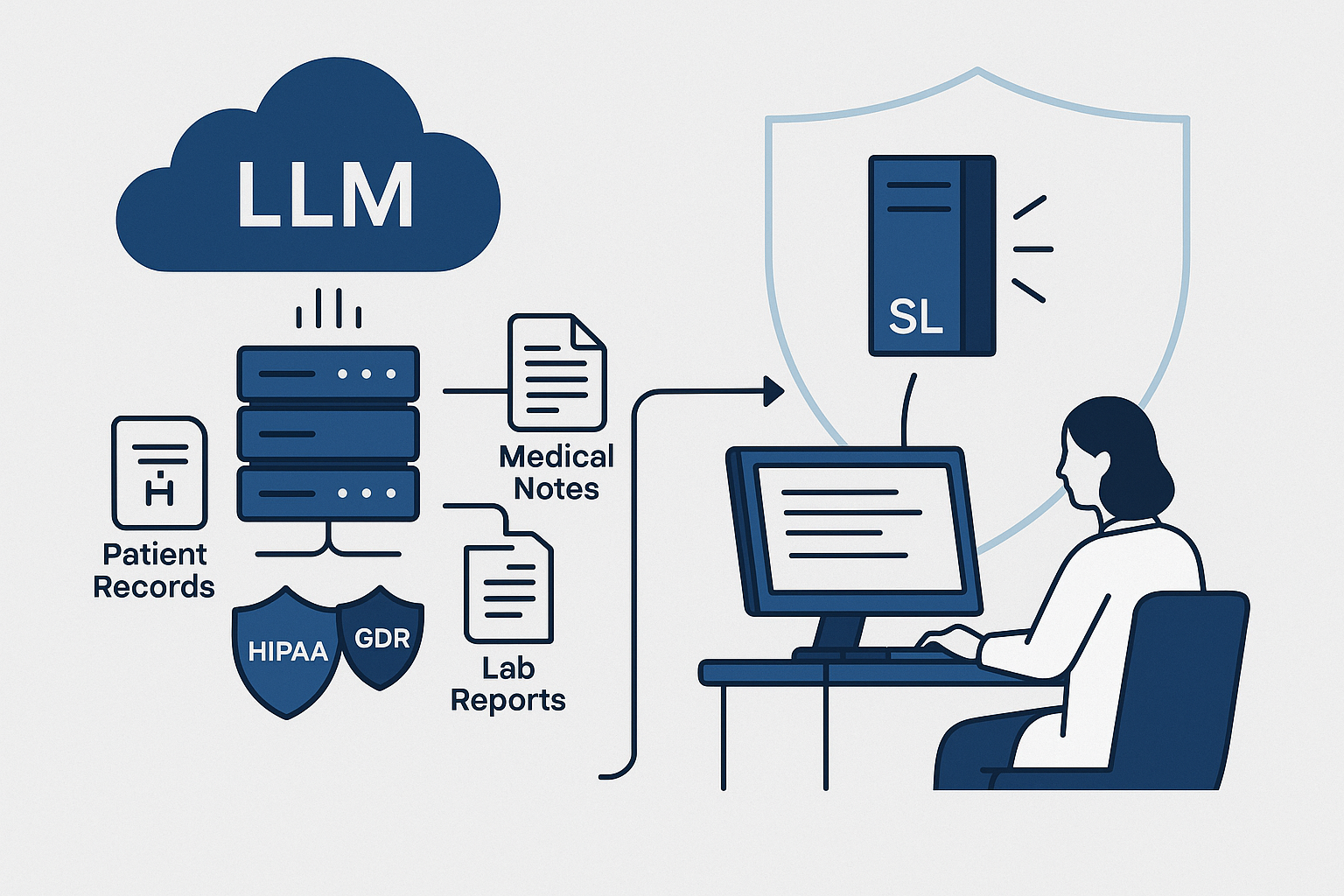
Executive Summary
Over the past two years, we have been exploring how AI in healthcare can be advanced using large language models. Our journey began with early models like BERT and has since expanded to deploying larger models locally within secure intranets, ensuring compliance with strict data privacy requirements. Along the way, we benchmarked models across both general and medical tasks, navigated challenges related to context length and efficiency, and eventually adopted quantized models that made real-world deployment practical.
This work has not been theoretical. Healthcare produces vast amounts of unstructured text, and nearly 80% of clinical data exists in free-form notes, patient histories, and diagnostic records. Making sense of this data is essential, yet few models are built to handle the complexity. Our early experiments showed both the potential and the shortcomings of different approaches, and each step provided lessons that shaped the path forward.
Looking ahead, we see enormous promise in Small Language Models (SLMs). NVIDIA and other leaders have highlighted how these models are faster, more cost effective, and better suited for on-premises healthcare applications. A 7B parameter model, when quantized and optimized, can deliver real-time performance on mid-tier hospital servers at a fraction of the cost of a 70B model. For healthcare organizations balancing limited IT budgets with the need for trustworthy AI, this is a critical development.
With these lessons, we now bring both technical expertise and practical perspective to building AI products that are not only powerful, but also responsible, efficient, and ready for clinical use.
1. The Early Days: Starting With BERT
We began our journey with BERT, one of the most widely used open-source models for natural language understanding. The hope was that it could help parse clinical notes and extract insights from free form patient histories. Healthcare generates a massive amount of unstructured data, and more than 80% of clinical information lives in physician notes, intake forms, discharge summaries, and lab reports. If a model could reliably interpret even a fraction of that data, the potential to reduce administrative bottlenecks and improve decision making would be significant.
In practice, BERT did not take us far. The model performed well on short and structured pieces of text, but healthcare conversations are rarely a sentence or two. They span entire patient histories, often thousands of words long, filled with subtle cues and evolving narratives. Without that broader context, BERT fell short.
This gap has been echoed by clinical NLP teams working with MIMIC III and similar datasets. Early experiments showed acceptable classification on narrow tasks, yet performance dropped when longer narratives and cross visit context were required. The takeaway was clear. Any AI system that hopes to be clinically relevant must retain and interpret longitudinal context across complex records.
“Healthcare conversations are never just one sentence — they are entire patient stories.”
2. Moving to Larger LLMs
The limitations of BERT pushed us to explore larger language models. When we began experimenting with a 7B parameter model, the shift was immediately noticeable. For the first time, the model could carry context across longer passages and make connections instead of treating everything as isolated fragments. It could understand patient histories as narratives rather than as scattered pieces of data.
This progression aligned with a broader trend in healthcare AI. A 2023 survey by Bain & Company found that 64% of health systems were already experimenting with large language models, but most cited privacy and compliance as the primary barriers to adoption. These concerns quickly became part of our own journey. One of our customers made a non-negotiable request: their data had to remain entirely inside their secure network. Sending information outside or allowing it to be used for generic training was not acceptable.
That requirement eliminated many popular cloud-based AI services. Instead, we deployed the model locally on their intranet. This was technically demanding, requiring careful infrastructure design, but it gave the customer confidence that their data remained private. It also taught us a valuable lesson: in healthcare, building trust is just as important as building capability.
Real-world examples reflect the same reality. The Mayo Clinic, for instance, has publicly discussed its exploration of on-premises deployments for sensitive patient records, citing the need to comply with HIPAA and internal security standards. These kinds of projects show why technical capability alone is never enough. For healthcare adoption, privacy and trust often determine whether innovation is even possible.
3. Benchmarking and Evaluation
Selecting the right model was never just intuition. We evaluated models across complementary benchmarks to understand general ability, clinical knowledge, and performance on real world data.
- General performance
MMLU, GLUE, HumanEval, and OpenLLM leaderboards helped us assess reasoning, logic, and code generation. MMLU spans 57 subjects including medicine and remains a practical reference point when comparing models that will be used in mixed clinical and operational settings. - Reasoning and multimodal
MMMU tested how models integrate multiple input types, which mirrors healthcare reality where text must be interpreted alongside vitals, labs, and imaging summaries. - Medical benchmarks
MedQA built on USMLE style questions, PubMedQA, and MedMCQA showed how well models handled domain specific knowledge. Even top models typically land around 67 to 75% on MedQA, which is below the passing threshold for licensed physicians and reinforces the need for clinical oversight. - Clinical datasets
MIMIC III and MIMIC IV exposed models to de identified patient records across thousands of ICU stays. These datasets surface the messy, longitudinal nature of notes and orders that any production system must handle.
Benchmarks gave us a shared language and guardrails, but they did not replace judgment. Peer reviewed work has shown that high performing models can still produce clinically incomplete or incorrect answers in a meaningful minority of cases. Our own experiments confirmed that safe deployment depends on governance, workflow design, and human review.
“Benchmarking gave us data, but judgment still mattered.”
4. The Challenge of Context Length
Context length became a major hurdle. Input and output limits varied across models. Some could carry long patient histories while others truncated or lost coherence. Outputs ranged from sharp and concise to rambling and incomplete. In healthcare, where a single overlooked detail can change a diagnosis, this was a barrier to safe adoption.
Patient records are long and scattered across encounters. A typical clinical note often runs well beyond one thousand words, and a longitudinal history can span many visits. A single allergy recorded years earlier or a brief note about a past adverse reaction may sit deep in the chart. Models that cannot retain this context risk missing information that matters.
This pushed us to think beyond raw model performance and into workflow design.
- Should we process entire histories at once or break them into structured pieces that a model can digest more effectively
- Would clinicians prefer shorter and more frequent outputs instead of one long report
These design questions became just as important as context length itself. In oncology and other complex specialties, physicians already spend hours each day navigating fragmented notes. Without models that can handle extended context and return focused summaries, AI would add noise rather than clarity.
5. Becoming Resource Efficient
Over time, new techniques allowed us to make better use of infrastructure. Quantized models became especially important, enabling us to run powerful LLMs on smaller and more cost-effective hardware. By reducing precision, these models cut memory use and improved inference speed without a significant loss of accuracy.
This shift mattered for healthcare customers who required on-premises solutions. Hospitals and health systems often operate with constrained IT budgets, and deploying massive models was not realistic. Quantization created a turning point where advanced AI became deployable even on mid-tier servers.
- Quantized models such as Q4 reduced memory usage by as much as 75% and inference costs by 40 to 60% according to NVIDIA and AWS reports
- This efficiency meant that a 7B parameter model could run locally with performance close to larger LLMs, yet at a fraction of the infrastructure requirement
- For healthcare, this translated into faster deployment cycles, lower capital expense, and wider accessibility for community hospitals and mid-sized providers
A real-world example comes from European hospitals that began testing quantized models for radiology reporting. Instead of investing in cloud GPUs, they leveraged optimized models to generate preliminary imaging summaries in house. The results were not only cost savings but also stronger compliance since patient data never left the hospital network.
Efficiency is not just a technical win. In healthcare, it becomes a matter of equity. By lowering the compute and cost barrier, resource efficient models give smaller organizations access to AI capabilities that were once limited to the largest systems.
6. Balancing Innovation and Safety
None of these steps came without tradeoffs. Larger models demanded more compute power, training required careful handling of sensitive data, and every system needed rigorous testing to avoid inaccurate or misleading results. At times it felt like walking a tightrope, moving fast enough to innovate while being careful enough to protect patient trust and safety.
In healthcare, safety is never optional. Research has shown that even advanced models can return clinically incorrect or incomplete information in 15 to 20% of cases. A study published in Nature in 2023 highlighted that GPT-4 produced hallucinations in medical question answering tasks at a rate that would be unacceptable in real care settings. These findings confirmed what we saw in our own work. Every new model required not only benchmarking but also structured governance, human oversight, and clinical validation.
Examples from the field reinforce this. When Google introduced Med-PaLM 2, tuned specifically on medical data, it demonstrated stronger performance compared to general LLMs. Even then, researchers emphasized the need for physician review before outputs could be used in clinical workflows. Similarly, Cleveland Clinic reported that in its exploration of generative AI for documentation, strict human-in-the-loop protocols were essential to preserve patient safety.
Balancing innovation with safety means treating every deployment as a complete system, not just a model.
- Data must remain compliant with HIPAA and international privacy regulations
- Models must be tested against diverse datasets to reduce bias and strengthen reliability
- Clinical staff must be involved throughout evaluation to ensure technology reflects medical realities
The lesson was clear. Innovation without safety undermines trust, and in healthcare trust is the currency that determines whether adoption happens at all.
7. What We Learned
Looking back, our journey has not been about chasing the biggest model. It has been about finding the right fit for healthcare environments. Each step taught us something important about language, medicine, and the balance between the two.
The most important lesson has been humility. These models are powerful but imperfect. They can accelerate clinical workflows and reduce administrative strain, but they cannot replace the responsibility of human judgment. In healthcare, every decision ultimately affects patients, which means responsibility must sit at the center of every design choice.
Several lessons became clear through our early experiments.
- Larger models created stronger performance on reasoning tasks but demanded compute and infrastructure that many hospitals could not sustain
- Benchmarking gave us direction, yet it never replaced the need for clinical oversight and human validation
- On premises deployment became critical for institutions that valued privacy and compliance above convenience, and in many cases this determined whether adoption was even possible
- Efficiency breakthroughs such as quantization proved that hospitals with modest resources could still access advanced AI, making equity a real consideration rather than an afterthought
The broader healthcare field reflects these lessons as well. In a 2023 Deloitte survey, more than 60% of healthcare executives said that responsible adoption of AI would require strong governance and clinician involvement at every step. This mirrors our own conclusion. The work is not only about capability. It is about responsibility.
“AI in healthcare is not just about capability; it is about responsibility.”
8. The Rise of Small Language Models (SLMs)
Recent research by NVIDIA and others has highlighted the promise of Small Language Models, or SLMs. These models are compact, run on consumer grade hardware, and deliver very low latency. In most current systems, every task is routed through massive models such as GPT-4 or Claude. NVIDIA argues that this approach is wasteful and unnecessary. Instead, they propose a modular design where smaller models take the lead and larger models are reserved for the most complex cases.
Why this matters for healthcare is clear.
- Efficiency and cost: Running a 7B parameter SLM can be many times cheaper than relying on a 70B or 175B parameter LLM. Reports from NVIDIA suggest cost reductions of 70% or more in both training and inference cycles.
- Flexibility: SLMs can run directly at the edge, which makes them ideal for on premises deployments where patient data cannot leave the hospital network.
- Modular design: Lightweight models can manage routine tasks such as summarizing visits, parsing lab results, or answering common administrative queries, while larger models can be called only for advanced reasoning or multimodal analysis.
For healthcare organizations, this shift could be transformative. Many administrative and clinical workflows do not require a massive model to deliver value. SLMs provide speed, efficiency, and privacy in one package, aligning with the needs of hospitals that operate under strict regulatory requirements and limited budgets.
Examples of this shift are already beginning to surface. Researchers at Stanford demonstrated that smaller domain specific models could outperform much larger LLMs when fine tuned on clinical data, particularly for tasks like triage classification and symptom extraction. Community hospitals in Europe have also begun testing quantized 7B models to power bedside decision support without cloud dependency. These early results suggest that the future of healthcare AI may not rest on scale alone, but on the smart use of smaller and more efficient intelligence.
9. Key Future Pillars
As we look ahead, several pillars will shape the next phase of AI in healthcare. These are not abstract concepts but practical priorities that determine whether adoption can be both impactful and responsible.
- Domain specific fine tuning: General purpose models have limits in medical accuracy. Fine tuning on curated datasets such as MIMIC-IV or PubMed has already shown improvements of 15 to 20% on clinical benchmarks like MedQA. Google’s Med-PaLM 2 is an example of how domain adaptation can bring models closer to clinical reliability, though human oversight remains essential.
- Multimodal AI: Healthcare rarely operates on text alone. Combining language with medical images, patient signals, and device data opens new frontiers. For example, multimodal systems have been piloted in radiology where models analyze imaging alongside structured notes to provide richer diagnostic support. In neurology, research teams are testing multimodal approaches that merge EEG signals with patient records to improve early detection of seizure risk.
- Efficiency first modeling: The healthcare sector cannot afford to run every task through massive infrastructure. Techniques like quantization and modular SLMs can reduce hardware requirements by more than half while maintaining high accuracy. A pilot at a European hospital demonstrated that running quantized 7B models on mid range servers reduced inference time by 60% while keeping performance close to state of the art.
- Trust and regulation: Healthcare AI is classified as high risk under the EU AI Act and must comply with HIPAA in the United States. This makes transparency, auditability, and explainability central to any deployment. Patients and providers alike need to know not only that outputs are accurate, but also how decisions are reached. Cleveland Clinic’s work with generative AI for documentation highlighted the importance of patient consent and clear communication when AI is in use.
- Modular agent design: Instead of one model attempting to do everything, future systems will orchestrate multiple agents. Smaller models can handle everyday administrative work such as scheduling or insurance verification, while larger models can be reserved for complex reasoning and diagnostic support. This approach mirrors how clinical teams operate, with routine tasks delegated and specialists called upon when complexity arises.
These pillars mark a shift from raw scale to purpose built intelligence. For healthcare, the future is not about chasing the largest models, but about building systems that are efficient, responsible, and clinically aligned.
Conclusion
Our journey with AI in healthcare is far from over. Every benchmark, every deployment, and every tradeoff has taught us something about how language models and healthcare realities intersect. The lesson has not been about chasing the biggest system, but about learning to balance scale with responsibility, and innovation with trust.
The future of AI in healthcare will not be defined by raw compute power alone. It will be shaped by domain expertise, workflow integration, and above all, patient safety. Small Language Models, efficiency first design, and modular agents offer a path toward AI that is affordable, compliant, and practical for real world healthcare environments. Hospitals and clinics will not adopt these technologies because they are powerful in isolation, but because they are reliable, explainable, and respectful of patient trust.
At CitrusBits, we take these lessons forward with humility and purpose. Our goal is not to build technology for its own sake, but to deliver systems that clinicians can depend on, patients can trust, and organizations can deploy responsibly. AI in healthcare is not only about capability. It is about responsibility, and it is about impact on real lives.
The road ahead is both challenging and exciting. With every iteration, we move closer to AI that is powerful, efficient, and deeply aligned with the needs of healthcare. And while the models will continue to evolve, our focus remains constant: to build responsibly, to innovate with care, and to always keep patients at the center of every decision.
“The measure of success for AI in healthcare is not in how advanced the model becomes, but in how much more time it gives back to patients and providers.”
About the Author

CitrusBits
Content Writer
Lorem ipsum dolor sit amet consectetur. Odio ullamcorper enim eu sit. Sed sed sociis varius odio vitae viverra. Eu sapien at vitae vulputate tortor massa semper vel. Lectus sed gravida blandit lorem consequat erat integer non ut. Morbi amet dui cras posuere venenatis. Laoreet sapien lacus sit sit elementum risus massa auctor. Enim ornare pharetra quis massa fusce. Nibh vitae in erat ut mollis erat. Amet cursus ut sem condimentum ultrices. Felis morbi malesuada sit amet ultrices at ut consectetur.
Related blogs

September 30, 2025
BLOG
